实现正则表达式的想法很早就有,各种原因导致没有做,最近花了点时间先实现了几个简单的正则语法,分别是concatenation、alternation和closure,其他语法及metacharacter等有时间了有想法了之后再扩展。
这三种基本的语法分别是对应这样的:
concatenation: abc 表示匹配字符串abc
alternation: abc|def 表示匹配字符串abc或者def
closure: a* 表示匹配零个到多个a构成的字符串
我们知道正则表达式最终需要转换成自动机才能用来匹配字符串,我实现的正则通过如下几个步骤把正则表达式转换成自动机:
正则表达式->Parse成AST->生成边 (字符) 集合->生成NFA->NFA subset construction->转换成DFA->DFA minimization
最后用DFA minimization之后构造的自动机来匹配字符串。
正则语法的分析
一个正则表达式写出来,要让这个正则表达式匹配字符串等操作之前,我们先需要从正则表达式中提取需要的信息并在正则语法错误的时候提示错误,这个过程自然少不了parser。一个parser通常是从一个lexer里面获取一个token,而正则表达式的token都是字符,那么lexer不需要做任何的分词操作,只需要简单的把字符返回给parser即可。
那三种基本的正则语法对应的BNF为:
re ::= alter
re_base ::= char | char_range | '(' re ')'
alter ::= alter_base alter_end
alter_base ::= concat
alter_end ::= '|' alter_base alter_end | epsilon
concat ::= concat_base concat_end
concat_base ::= re_base | closure
concat_end ::= concat_base concat_end | epsilon
closure ::= re_base '*'
这个parser分析了正则表达式之后产生AST,AST的node类型为:
class ASTNode
{
public:
ACCEPT_VISITOR() = 0;
virtual ~ASTNode() { }
};
class CharNode : public ASTNode
{
public:
explicit CharNode(int c) : c_(c) { }
ACCEPT_VISITOR();
int c_;
};
class CharRangeNode : public ASTNode
{
public:
struct Range
{
int first_;
int last_;
explicit Range(int first = 0, int last = 0)
: first_(first), last_(last)
{
}
};
CharRangeNode() { }
void AddRange(int first, int last)
{
ranges_.push_back(Range(first, last));
}
void AddChar(int c)
{
chars_.push_back(c);
}
ACCEPT_VISITOR();
std::vector<Range> ranges_;
std::vector<int> chars_;
};
class ConcatenationNode : public ASTNode
{
public:
void AddNode(std::unique_ptr<ASTNode> node)
{
nodes_.push_back(std::move(node));
}
ACCEPT_VISITOR();
std::vector<std::unique_ptr<ASTNode>> nodes_;
};
class AlternationNode : public ASTNode
{
public:
void AddNode(std::unique_ptr<ASTNode> node)
{
nodes_.push_back(std::move(node));
}
ACCEPT_VISITOR();
std::vector<std::unique_ptr<ASTNode>> nodes_;
};
class ClosureNode : public ASTNode
{
public:
explicit ClosureNode(std::unique_ptr<ASTNode> node)
: node_(std::move(node))
{
}
ACCEPT_VISITOR();
std::unique_ptr<ASTNode> node_;
};
其中ASTNode作为AST的基类,并提供接口实现Visitor模式访问ASTNode类型。
字符 (边) 集的构造
AST构造好了之后,需要把AST转换成NFA。语法中有[a-zA-Z0-9]这种字符区间表示法,我们可以用最简单原始的方法转换,就是把区间中的每个字符都转化成相应的一条边 (NFA中的边) ,这样一来会导致字符区间越大,对应边的数量会越多,使得对应的NFA也越大。因此,我们需要构造区间字符集合来减少边的数量。
比如正则表达式是:a[x-z]|[a-z]*e
那么我们希望对应的字符集合是这样:{[a-a] [b-d] [e-e] [f-w] [x-z]}
这需要构造一个字符集,每次插入一个区间的时候,把新插入的区间与已存在的区间进行分割,初始时已存在的区间集为空,那么正则表达式a[x-z]|[a-z]*e的划分步骤如下:
已存在区间集合{},插入[a-a],得到{[a-a]}
已存在区间集合{[a-a]},插入[x-z],得到{[a-a], [x-z]}
已存在区间集合{[a-a], [x-z]},插入[a-z],得到{[a-a], [b-w], [x-z]}
已存在区间集合{[a-a], [b-w], [x-z]},插入[e-e],得到{[a-a], [b-d], [e-e], [f-w], [x-z]}
这个区间构造完成了之后,还需要在后面转换成NFA边的时候,根据字符区间查询出在这个集合中,由哪几个区间构成,比如:
查询区间[a-a],得到[a-a]
查询区间[x-z],得到[x-z]
查询区间[a-z],得到区间[a-a] [b-d] [e-e] [f-w] [x-z]
在转换成NFA时,集合中的每个区间都对应一条边,这样相对于每个字符对应一条边,边的数量不会太多。
有了这么一个集合构造的类之后,把正则的AST中的字符信息提取出来构造出这么个集合即可,这样只需要写个visitor就完成了:
class EdgeSetConstructorVisitor : public Visitor
{
public:
explicit EdgeSetConstructorVisitor(EdgeSet *edge_Setter)
: edge_Setter_(edge_Setter)
{
}
EdgeSetConstructorVisitor(const EdgeSetConstructorVisitor &) = delete;
void operator = (const EdgeSetConstructorVisitor &) = delete;
VISIT_NODE(CharNode);
VISIT_NODE(CharRangeNode);
VISIT_NODE(ConcatenationNode);
VISIT_NODE(AlternationNode);
VISIT_NODE(ClosureNode);
private:
EdgeSet *edge_Setter_;
};
边集合构造完成之后,下一步就是生成NFA了。
生成epsilon-NFA
epsilon-NFA是包含epsilon边 (空边) 的NFA,把简单正则表达式转换成epsilon-NFA的方法如下:
- 正则表达式:ab 对应的epsilon-NFA是:
- 正则表达式:a|b对应的epsilon-NFA是:
- 正则表达式:a* 对应的epsilon-NFA是:
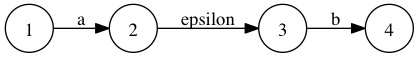
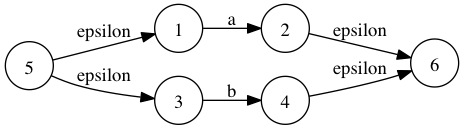
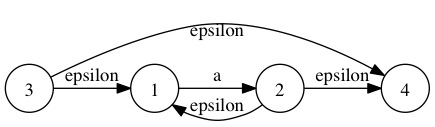
这是最基本的3种正则表达式的NFA表示,其中a*在实际的正则表达式实现中通常生成的epsilon-NFA不是这样的,因为有下面这些正则表达式存在:
a{m} 重复a,m次
a{m,n} 重复a,m到n次
a{m,} 重复a,至少m次
a+ 重复a,至少1次
a? 重复a,0次或1次
所以对于a*表示重复至少0次的实现可以跟上面这些正则表达式采用相同方法的实现。
按照这些生成规则就可以把正则表达式转换成epsilon-NFA,我代码中即把这些生成规则实现成一个AST的visitor。
epsilon-NFA subset construction to DFA
在生成了epsilon-NFA之后,通常会有很多epsilon的边存在,也会有很多无用的state存在,所以通常需要把epsilon边消除并合并state,这个过程采用的算法是subset construction,如下:
subset construction:
// 把start_state通过epsilon扩展得到起始subset
start_subset <- epsilon_extend(start_state)
// 初始化subsets
subsets <- { start_subset }
// 初始化work_list
work_list <- subsets
while (!work_list.empty())
{
subset <- work_list.pop_front()
// 取出NFA中的每条边
for edge in epsilon-NFA
{
// 对subset中的每个state通过edge所到达的
// state的epsilon边扩展得到next_subset
next_subset <- delta(subset, edge)
// 如果next_subset不存在于subsets中,
// 则把这个next_subset加入到work_list中
if (!subsets.exist(next_subset))
work_list.push_back(next_subset)
// 构建subset到next_subset的边映射
map[subset, edge] = next_subset
// 把next_subset合并到subsets
subsets.merge({next_subset})
}
}
delta:
// 初始化next_subset为空集合
next_subset <- { }
for state in subset
{
// 取出next_state并将它通过epsilon
// 边扩展得到的subset合并到next_subset中
next_state <- map[state, edge]
if (next_state)
next_subset.merge(epsilon_extend(next_state))
}
这里面使用了epsilon_extend,它是把一个state的所有epsilon边能到达的state构成一个集合,比如上面正则表达式a*对应的epsilon-NFA中的所有state的epsilon_extend是:
epsilon_extend(1) –> { 1 }
epsilon_extend(2) –> { 1, 2, 4 }
epsilon_extend(3) –> { 1, 3, 4 }
epsilon_extend(4) –> { 4 }
对于一个epsilon-NFA来说,每个state的epsilon_extend是固定的,因此可以对epsilon-NFA中的每个state都求出epsilon_extend并保存下来,算法如下:
epsilon_extend_construct:
work_list <- { }
// 为每个state初始化epsilon_extend集合
for state in epsilon-NFA
{
epsilon_extend(state) <- { state }
work_list.push_back(state)
}
while (!work_list.empty())
{
state <- work_list.pop_front()
state_epsilon_extend <- epsilon_extend(state)
// 把state通过epsilon所能到达的state的epsilon_extend
// 合并到当前state的epsilon_extend
for next_state in map[state, epsilon]
state_epsilon_extend.merge(epsilon_extend(next_state))
// 如果当前state的epsilon_extend变化了之后
// 把所有通过边epsilon到达state的pre_state都加入到work_list中
if (state_epsilon_extend.has_changed())
{
for pre_state in epsilon_pre(state)
work_list.push_back(pre_state)
}
}
epsilon-NFA通过subset construction构造成完之后,并把构造的subsets中的subset转换成DFA中的state,再把NFA中除epsilon边之外的所有边都转换成DFA的边,这样就把DFA构造完成。
DFA minimization
从NFA构造完成DFA之后,这时的状态数量一般不是最少的,为了减少最终生成的状态机的状态数量,通常会对DFA的state进行最小化构造,这个算法具体如下:
minimization:
// 把所有state划分成accept的state集合和非accept的state集合
state_sets <- { {accept_state(DFA)}, {non_accept_state(DFA)} }
do
{
work_list <- state_sets
old_state_sets_size <- state_sets.size()
state_sets <- { }
for state_Setter in work_list
{
split_success <- false
for edge in DFA
{
// 如果edge可以把state_set拆分成两个subset,那就把新拆分出来的
// 两个subset合并到state_sets里面,并break继续work_list中取出下一个
// state_set拆分
subset1, subset2, split_success <- split(state_Setter, edge)
if (split_success)
{
state_sets.merge({subset1, subset2})
break
}
}
if (!split_success)
state_sets.merge({state_Setter})
}
} while (old_state_sets_size != state_sets.size())
这里面的split是把一个state_set按edge划分成两个subset,即对于state_set中的每一个state都通过这条边edge到达的state属于不同的state_set时就把state_set拆分成两个subset。首先把第一个state划分到subset1中,从第二个state开始通过边edge到达的state所属的state_set和第一个state通过边edge到达的state所属的state_set为同一个的时候,把这个state划分到subset1中,否则划分到subset2中。
这个算法就这样依次把最初的两个state_set (accept的state组成的Setter和非accept的state组成的Setter) 划分到不能再划分为止,此时就把能合并的state都合并到了同一个state_set中,这时只需要把每个state_set转换成最终状态机中的state,即可完成DFA的最小化构造并转换成状态机。得到状态机之后,就可以使用状态机进行字符匹配了。
正则引擎常见的实现方法
正则的常见实现方式有三种:DFA、Backtracking、NFA:
DFA是三种实现中效率最高的,不过缺点也明显,一是DFA的构造复杂耗时,二是DFA支持的正则语法有限。在早期正则被发明出来时,只有Concatenation、Alternation、Kleene star,即ab a|b a*,DFA可以轻松搞定。随着计算机的发展,正则像所有其它语言一样发展出各种新的语法,很多语法在DFA中难以实现,比如capture、backreference (capture倒是有论文描述可以在DFA中实现) 。
Backtracking是三种实现中效率最低的,功能确是最强的,它可以实现所有后面新加的语法,因此,大多数正则引擎实现都采用此方法。因为它是回溯的,所以在某些情况下会出现指数复杂度,这篇文章有详细的描述。
NFA(Thompson NFA)有相对DFA来说的构造简单,并兼有接近DFA的效率,并且在面对Backtracking出现指数复杂度时的正则表达式保持良好的性能。
NFA-based的实现
这里描述的NFA是指Thompson NFA。Thompson NFA实现的核心是对于正则表达式多个可能的匹配并发的向前匹配,此过程是在模拟DFA运行。比如对于正则表达式abab|abbb匹配字符串abbb:
Backtracking的匹配过程是取正则的第一个子表达式abab匹配,前两个字符匹配成功,匹配第三个字符的时候失败,这时引擎回溯选择第二个子表达式abbb匹配,最终匹配成功。
Thompson NFA是同时取两个子表达式abab和abbb匹配,前两个字符匹配时,两个子表达式都能匹配成功,当匹配第三个字符时,子表达式abab匹配失败,因此丢弃,abbb匹配成功接着匹配,最终匹配成功。
上面是一个简单的例子,没有出现* + {m,n}这种复杂的metacharacters,在处理这种repeat的metacharacter时Thompson NFA优势更加明显。
在实际复杂的正则表达式中,NFA构造是必然会产生一堆epsilon边,这在第二篇文章中有描述。上面描述Thompson NFA实际是在模拟DFA运行,在每个字符匹配完成之后需要跳过epsilon边得到后面要匹配的并发的状态集合,这样持续的并发匹配下去,当字符串匹配完成时只要有一个达到了接受状态,就是匹配成功,若这个集合为空,那表示匹配失败。
在我的实现中,构造了一组状态和由这组状态加epsilon边集合构造的有向图,每个状态有自己的状态类型,分为两种:
一种是匹配状态类型,即用来匹配字符的状态,若字符匹配成功,则进入下一个状态;
一种是操作状态类型,即不匹配字符的状态,在每个字符匹配结束之后若到达这些状态,则会进行相应的操作,比如repeat状态,记录匹配计数,并判断匹配计数是否完成再决定是否进入的下面的状态。
repeat是一种会分化的状态,达到最小匹配次数时,可以接着往下走,也可以继续重复匹配repeat的子正则表达式,这样就分化成两条线了,并且每条线都带有自己的状态数据,因此,我的实现中引入的thread来表示一条匹配线,里面有状态数据。
Match和Search
状态构造完成了之后,就要开始匹配了。匹配有两种,一种是match,即一个正则表达式能否完整匹配一个字符串,若完整匹配则匹配成功;另一种是search,要在一个字符串中或者一块buffer中查找每个满足的匹配。这里就有个问题,从第一个字符开始匹配,匹配了几个字符之后发现匹配失败了怎么办呢?回退到第二个字符重新匹配?我们知道对于普通的字符串查找,有KMP算法可以保证不回退字符 (其实KMP算法的预处理就是构造DFA) ,或者有Boyer-Moore算法尽量回退少的字符个数。对于正则这种复杂的匹配该怎么办呢?从上面的Thompson NFA的描述可以知道匹配过程是多条线并发匹配,因此可以构造一个始终产生一条新线的状态,若匹配在前面的线失败被丢弃之后,后面的新线始终可以补上,这样查找的过程就不再需要回退字符了。
我的实现中,状态构造完成后是这样的:
// |-----|--------|---------------|-----|-------------|
// | any | repeat | capture begin | ... | capture end |
// |-----|--------|---------------|-----|-------------|
用repeat-any来产生新的匹配线。若在match模式下,则从第三个状态开始匹配,不会产生新的匹配线,一旦匹配过程失败了就失败了。
结语
正则表达式语法一直在扩展,新的语法有些很难在DFA和NFA中实现,而在Backtracking中的实现又是以牺牲性能为代价。因此有些正则表达式实现会结合多种实现方式,判断正则表达式的类型选择不同的引擎,比如普通字符串加上一些简单的正则语法采用DFA引擎匹配,或者只有普通字符串的匹配可以用Boyer-Moore算法,毕竟Boyer-Moore算法在普通文本查找中要优于KMP算法:) ,对于复杂的正则表达式采用Backtracking,甚至有些正则引擎使用JIT来加速。



